I’ve recently started a journey of using DNA to further my family tree research. I have an extensive paper trail family tree from many years of research, but I was really interested in what science could offer in terms of using a DNA test to find cousins and confirm who I thought were my family. DNA testing is relatively new for genealogical purposes but it has been of huge interest to adoptees (of which I’m not – I know my biological family) for obvious reasons. The goal of DNA testing for genealogical purposes is to find the most recent common ancestor shared by you and the matches returned by the DNA testing company.
At first it seemed sensible enough, if DNA could prove who committed a crime, and prove paternity then surely it could be used to find family and prove family connections. Sure enough there is a particular type of testing that can be used for genealogical purposes. There are many types of DNA tests (not just genealogical ones) – but the one used for family history purposes is called an Autosomal DNA test. Basically this is not a full sequencing of our genome (that would cost an awful lot of money!) but it is a test that, put simply, just looks at what makes us different from each other. These differences we all have (red hair, big nose, long legs…) are inherited from our biological families. Within our DNA there are areas that have mutated over the years to create these differences in the human race. As DNA gets more and more randomised over each generation (and in fact more mutations start to occur), we can only really compare our differences from the past 5 or 6 generations – after that it is too mixed up and randomised to be useful for genealogical purposes (remember I’m only talking about genealogical DNA tests).
I needed to learn about how DNA is inherited so that I could understand what the tests were telling me. We inherit 50% of our father’s DNA and 50% of our mother’s DNA – after that DNA is quite random and mixed up. So the 50% of our mother’s DNA could be made up of a large portion of her mother and a small portion of her father. Although she inherited 50% of each parent it has been recombined before being passed on. So it is incorrect to assume that your DNA is exactly 25% of each grandparent, but you do know for sure that you have exactly 50% of each of your parents. If you google “DNA inheritance” you’ll find lots of charts that explain this is much more detail.
I took the DNA test initially at Ancestry – it was all quite simple, spit into a tube and mix in some stabilising solution (supplied) and put it back in the special postage box and drop it off at the post office. Samples are sent off to labs in the USA for testing in a pre-paid box that comes with the sample tube. It takes a few weeks for the sample to be processed, but after much anticipation the results were in. Initially when getting results, like most people I dived straight into what my ethnicity was – I was over 90% British, 5% Irish and 2% Finnish (so far the Finnish part is still a mystery – but I will touch on Ethnicity results later). Once I got over the excitement of ethnicity results I suddenly realised I was faced with a very long list of names of people who appeared to be related to me. These matches were listed in the order of closest matches (in Ancestry terms these were given a “Possible range” such as “Close family – 1st cousins” through to more distant cousins (“5th-8th cousins”). But that was it, what did it all mean? and how was I supposed to figure this out – none of these people (there were hundreds of them) were known to me. Now I have been doing family research for many years, so I was expecting (I think) to just see names that I already had in my tree, and simply match up that these cousins had the same paper trail as me, and we could confirm my years of research. It was NOT that simple, and I suddenly realised that I needed to understand more about how we matched and what made some people a closer match. How on earth would I sort all this out? Turns out I wasn’t the only person dazed and confused with my DNA test results! I joined a few facebook groups, started watching some videos and reading about genetics and DNA testing, and slowly the clouds cleared but it certainly is much more complex than I initially thought. I’m well on the way to confirming a lot of different matches and below is more about my journey. This is not written in a technical or scientific manner – I’ve attempted to write this as if we were just having a chat about it. Apologies if I’ve skimmed over some technical areas, or made a broad sweeping statement on something that is much more complex, it is my attempt to simplify the more complex information, with the hope that people may go on to learn more about the complexities of the subject (it really is fascinating).
Having learnt a bit about DNA, the next thing I went on to learn about was something about chromosomes – I had no idea how these worked, but they are basically what hold all this DNA. We have 46 chromosomes, 23 from each biological parent. Of the 23 chromosomes from each parent, 22 (44 in total) of them are called the “autosomes” (this is where the name autosomal test comes from). Chromosomes have areas where each human is different – these differences are called SNPs. (pronounced snips). If we are closely related to someone our differences are the same as their differences (ie red hair, big nose, long legs). The SNPs are the areas of DNA that are used for genealogical purposes and the various SNPs (differences) that are tested can be measured in a certain way that makes them comparable for close relatives. The measure used by the testing companies is a centiMorgan (cM) . This is not a simple measurement like inches, or a count of things. It’s a mathematical formula that works out what they call “genetic distance”. I found out that initially all I needed to know was that the more shared cM (the higher the number), the closer the match I was to someone (and the more likely we had a shared ancestor). There are in fact two cM numbers that are relevant in our DNA testing, the “total shared cM” and the “largest cM” sometimes called “longest block” (this is largest segment of DNA, or to put it simply where the shared DNA is all together and not split up). Full siblings have a lot of DNA in common (because they both got 50% from the same parents), they have a shared cM of around 2,550 but they are not identical because of the DNA inheritance and how the DNA passed on is randomised. Second cousins match at around 212.5cM. Sites like ISOGG wiki have charts that help us work out what the likely relationship of a match is, based on the total shared cM. These charts become invaluable to search for a common ancestor of you and your match as you need to know if you are looking for a common ancestor 1 generation back or 4 generations back. The higher the number the closer the match. http://www.isogg.org/wiki/Autosomal_DNA_statistics
For my test at ancestry, I realised that ancestry do not show any cM numbers [edit Jan/2016: from late 2015 Ancestry do now provide a total cM number for each match]. However they do produce a chart that shows what the cM numbers must be for them to class our matches into various categories of confidence and likely relationship (It is available on the Ancestry site). One of the other big 3 testing sites is ftDNA (familytreeDNA) – they do show all the cM numbers for your matches – on the initial page of matches they show the total shared cM and then by clicking below the match name you’ll see more detail including the more important longest block cM. 23andMe the other of the big 3, requires the match to allow you to see your matching details, they are not displayed initially. I could have just sat back and looked at the ancestry results, compared the detail they did let me see (and they do have a lot of information, it’s just they don’t share “the numbers”) and contact my matches to see if we could work out together who our common ancestor might be. Ancestry do offer some automated tools, they will give you a “hint” if your DNA match has the same paper trail as you, and they will also show you on a map where your matches paper trail locations are. They also show you a list of the surnames in the tree of your match. This assumes that the person who matches you, also actually has a public tree or has even done their family tree. It started to emerge that many of the testing sites do have problems in that people were not necessarily sharing their trees or replying to contact. Each of the testing sites vary in terms of what you can see or do with your DNA results. So although I had now learnt all about understanding autosomal DNA results, I was coming up against brickwalls in terms of knowing and tracking down who these matches were, let alone who our shared ancestor was.
My knight in shining armour was a site called GEDmatch (gedmatch.com). GEDmatch is run by volunteers and is free, it provides tools to help examine DNA matches closer, by providing detailed cM numbers and chromsome browsers to drill down to the detail of how you match someone. Up until this point the only site I had seen a chromosome browser on, was ftDNA. Ancestry do not have a chromosome browser and 23andMe do, but it requires your match to allow you to see their DNA results first. To be able to use GEDmatch I needed to send them (upload) my DNA results – this was actually very simple. Each of the big 3 testing sites allow you to download your DNA file, and GEDmatch is setup to take this download file and process it into their database – it is just a simple matter of registering on the site and going through their upload process (follow the links on their home page – you need to register first). Although by this stage I had test results at each of the big 3 sites, it is only necessary to upload one of your files (for the purposes of GEDmatch they are all identical). Speaking of testing on all sites, ftDNA site (www.familytreedna.com) offers an “autosomal transfer” – this means that if you have a test on ancestry you can upload it to ftDNA and they will process it into their database as if you had the test there. There is a cost for this but it is very small in comparison to actually doing their test. This means you can be in both the Ancestry and ftDNA database for the price of 1 test and a small additional fee. A bargain! I tested with 23andMe directly as I was becoming more and more interested in DNA and wanted to see how their tests and site worked. They have some have fun additions to their results including your Neanderthal percentage and other various things. 23andMe also offer heath testing (not available in all countries). I found this very interesting but will not be covering that in this blog post. All I would say is if you have any questions or concerns regarding health reports from your DNA test, then you need to discuss them with health professionals and not genealogists. If you want health results and have not tested with 23andMe, there are other sites available – you can google for them, but Promethease is a suitable alternative and you can upload your DNA file for a comprehensive health result for a very small price.
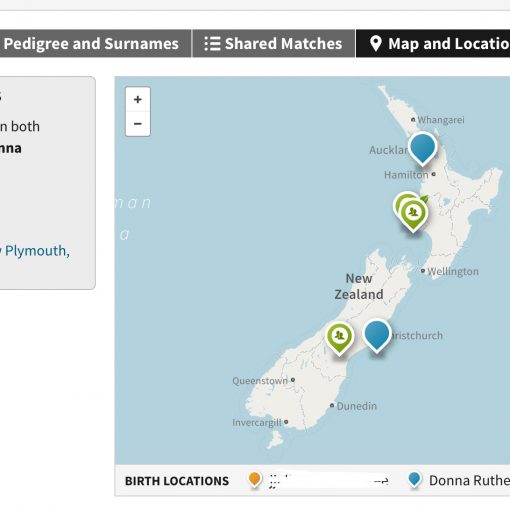
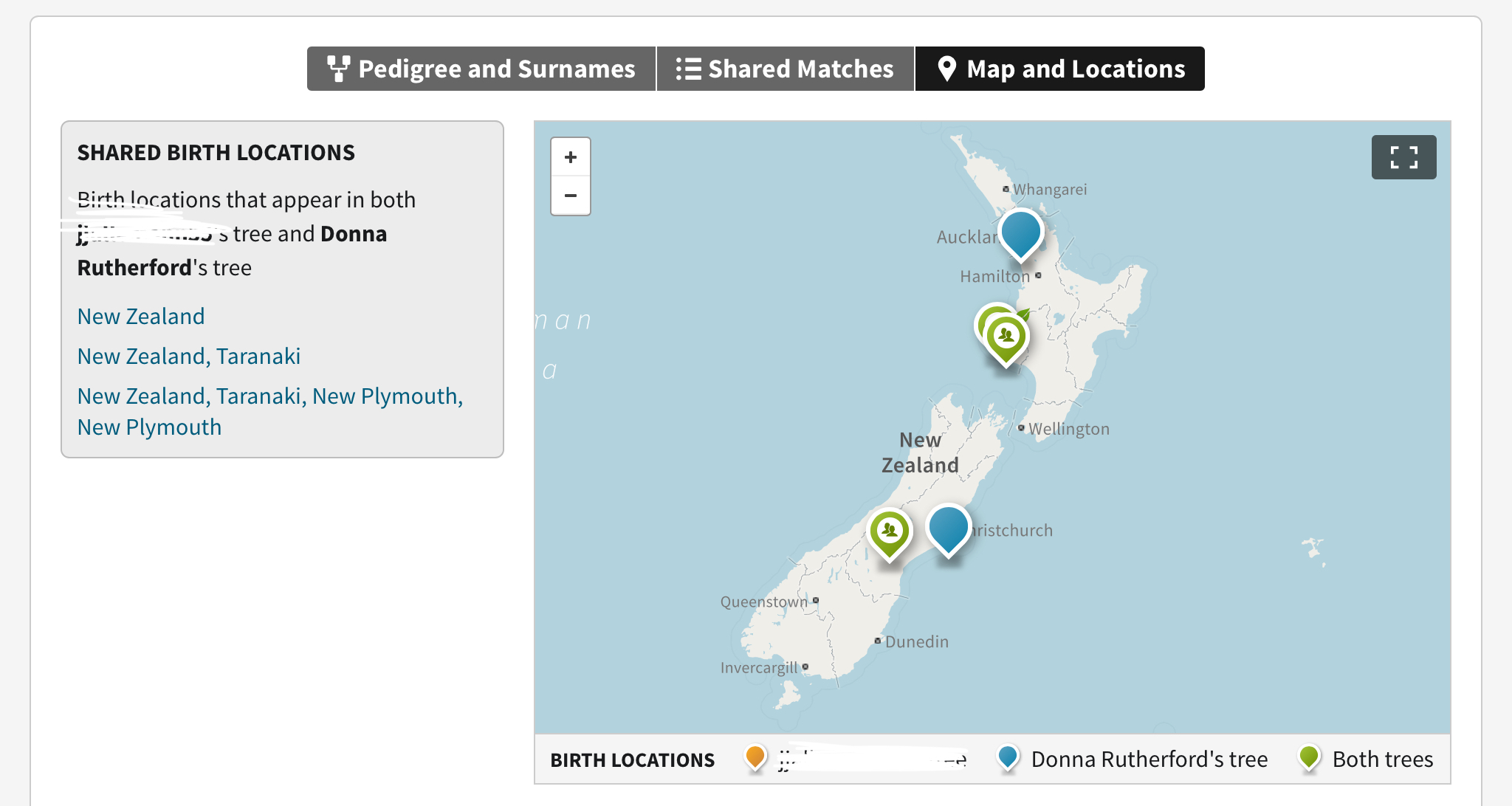
So back to GEDmatch – after a few days (although now it can sometimes only take a few hours) my data was processed and able to be analysed in a “‘One-to-Many’ matches” report. You can find this and other reports on the GEDmatch home page once you have registered and logged in. GEDmatch is more of a technical site than perhaps the nice user friendly interface of the testing sites themselves. There are some very good blogs about using GEDMatch but I will cover some of the tools I’ve used in the most simple way I can. There are 2 reports I’m going to cover – these are the ones that you will use the most when you first get started. The first report to run is the One-To-Many matches report. When you click on it the page opens and looks a bit complex to start with – but there is only one field you need to fill in and that is your KIT number. A KIT number is assigned to you by GEDmatch when go through the process of uploading your DNA file. You can upload files from any other relatives that you have tested and uploaded as well – they will all be available on the front page when you log in – each with their own KIT number. I now have both my maternal uncle and my son on GEDMatch [edit: Jan/2016 – I know have mother, sister, and several uncles on GEDMatch – I am truly addicted]. I’ll explain why you might want to test more family members – when you see your matches, you are unable to tell where they might match you, is a cousin on your fathers side or your mothers side? There is no way that the test can work this out for you. If you tested your mother for example, you would see that many of your cousin matches are also her cousin matches. (when I say cousin it may be first, second, third, 2nd 1 times removed etc…). When you looked at your mothers matches you know that that match comes from her side of the family. You can safely assume that the majority of matches that don’t match her must be from your fathers side. (I say the majority, because there could be several matches where the cM numbers are low and these may be coincidental that you match them, rather than because you have inherited that particular DNA from a common ancestor).
GEDmatch reports can be quite confusing to start with as they look like spreadsheets with lots of numbers. For an excel fan like me that was quite exciting, but I imagine that anyone who may not be so technical or mathematical, it might look hideously confusing. So lets breakdown what we actually see on these reports. By running a GEDMatch many to one report, you will get a list of 1500 matches – these are people that match your DNA and have also uploaded to GEDMatch. You can tell where these people did the actual test as the first column lists their kit number – a kit starting with A means it was an ancestry test, F for ftDNA and M for 23andMe tests. This can be useful to know if you are researching someone and want to try and look for them on the site they originally tested on. Especially useful if you have tested on the same site as them. Going across the page of the GEDmatch report you want to look across for those 2 important numbers – total cM and largest cM. GEDmatch will sort the report with the largest shared cM at the top. I like to re-sort the page by the largest cM, and it can be done by just clicking the little arrows in the top of that cell where the column name is. The next step I took when I first ran my reports, was to download this list of people to an excel spreadsheet. You can do this by just highlighting them all on your computer and copying and pasting them to a spreadsheet. The reason I did this was because they were now on my own computer, but also it meant I could add some columns to write notes next to each match, or I could highlight the names I knew, or the names I was more interested in researching. Because I couldn’t possible research 1500 names, I extracted the top few matches and put them into a new sheet – I called these my TOP MATCHES. I’ve since added to my top matches by adding matches from the test sites (although several of them were already in GEDmatch, so I only added those that weren’t – and again kept it only to the closest relationships). My Top Matches list is where I spend all my time now – I’m only working on matches that have the closest match, I’m not bothering (at the moment) with all the more distant cousins. It’s worth noting that 2nd cousins mean shared Great Grandparents, 3rd cousins means shared 2xG Grandparents and so on. Everyone has 4 grandparents, 8 G Grandparents, 16 2xG grandparents, 32 3xG grandparents and 64 4xG Grandparents – however this would be different if you have cousin marriages in your tree). It’s estimated that everyone has approximately 4,700 5th cousins, that is a lot of cousins that you potentially could get DNA matches with. It’s most likely that your paper trail family tree has many gaps in it and that you have not documented your family at this level right out through all branches. After many years of research I know that I do not have all that information, and some information I do have is quite sketchy due to unavailable records and incorrect information. It’s believed that we all have 2 family trees. Our documented genealogical family tree and now our genetic biological family tree. Whilst these may be the same, there is definitely room for them to be different, with illegitimate births, unknown parentage, adoptions, and the like. DNA testing is bringing several family secrets out into the open. You need to be prepared that you may find out things that were previously hushed up.
- I immediately start a family tree with my match at the bottom of the tree – I use ancestry for this – I set up a new tree and make sure it is private (and also go the extra step to stop it being found in searches).
- Look through the profile of the match – can you find them on sites other than ancestry, can you find clues as to their parents or grandparents? Google their email address this often pops up with some ancestry type sites they have listed their details in. If in Ancestry you can search their member profile for any hint of a surname they might be searching for. In ancestry sometimes it says they have no tree, but if you look their is one they have just not linked to it. Google their name (if you can figure out their actual name) – or just google their profile name. You are looking for any hints (obituary pages, research pages, social media sites, 192 type sites etc) where they mention their full name or better yet parents/grandparents name. Fill in their tree with what you find. Sometimes you only need 1 generation in a tree to start finding more – especially if you are on Ancestry as you start to immediately get hints to build up the tree. Hopefully this leads straight to a common ancestor.
- Look at a “cluster” of people – those all matching on a particular chromosome and are confirmed to all match each other. If you can find a link to one, you should find them all fitting into place. I do this work all on my excel spreadsheet – but there are other tools to help you do this – two of the tools that spring to mind are GenomeMate and DNAGedcom. These sites have applications that help effectively manage your top matches and keep track of where and how they all match you and each other. I use a spreadsheet because I like excel and I use it a lot in my worklife, so I have built my own chromosome browser. You don’t have to do this (and you probably shouldn’t) – you can use sites that have applications already set up to use.
- Rule out where the common ancestor CANNOT be. This will stop you searching your entire tree to find a common ancestor. If you have someone marked down as a paternal match, then anyone matching that person should also be a paternal match (there will be exceptions and keep an eye out where one-to-one matches show something you weren’t expecting). Keep your family charts in front of you when doing this. There is an additional test here that can also help you – and that is the results from the X-Chromosome. The X Chromosome is 1 of the pairs of sex chromosomes that come from your parents – 1 from each. Your mother (regardless of your sex) will ALWAYS pass down her X-Chromosome (which will be a randomised version of her 2 X chromosomes from her parents) and your father will pass down an X Chromosome if you are a female and a Y Chromosome if a male). Although DNA inheritance on the X Chromosome is somewhat different than the other 22 pairs of autosomes, it can be used to try and rule out some areas of the family tree that the match CANNOT be on, given a male will not get an X match with his father. So if you are male and share matching DNA on the X Chromosome, you know that match cannot be on the paternal side and you share a common ancestor on your mothers side. GEDmatch does show X matches and the amount of DNA shared – you can use the X match information for this purpose, but be aware of trying to use for anything else. Due to the inheritance pattern of X DNA the match may have come many many years ago (before paper trail genealogy timeframes).
- Test more of your family – it really is helpful to have another family member to test, if possible your mother or father. Their matches will also go back 5-6 generations so this will give you additional matches another generation back. Testing the oldest living relative as soon as possible, should be on all of our ToDo lists!. There is limited use in testing a sibling, as they will be have similar matches to you (although some additional due to DNA inheritance – ie. they will have different bits of your parents). A relative who is paternal or maternal is definitely going to help you sort matches into paternal/maternal, once you can establish which side your match is from then it immediately removes 50% of your tree you need to search for the most recent common ancestor. However whilst you can sensibly conclude that anyone who does not match your mother MUST come from your fathers side, you can not make the same assumption with an uncle or aunt. They will have different bits of DNA from your grandparents than you do. You only have approximately 25% of their parents DNA and you cannot tell which percentage you have.



{kind=link}
{kind=link}
18 thoughts on “Put the kettle on, lets sit down and talk about DNA (*for newbies only)”
I found this very helpful and well explained. Great job. I have one question. I tested with FTDna and got 37 marker test. I had a perfect match to all 37. I was told that taking additional marker test with a higher amount would be a waste of time since I had a perfect match with 37. Is this correct?
Thanks for your comment George. I confess to not be an expert on Y DNA, mostly because I’m female and have yet to have a male in my family take a Y-DNA test. However based on information I have read, at 37/37 markers you have a 50% probability that the most recent common ancestor was no further than 2-3 generations and a 90%-95% probability that the mrca (most recent common ancestor) was 8-10 generations away. Whereas 67/67 means you have a 50% probability that the mrca is 2 generations away and a 90-95% probability that the mrca is 6 generations away. I think you need to decide on the value to your research of of upgrading the test and being able to predict exactly how close the match is to you.
thanks for one of the best “cornbread” explanations I have read since starting to delve in this DNA stuff. I was already doing some of the things you suggested and you’ve given me reassurance I’m on the right track with more to do.
I do have one question that I had asked early on on one of the more advanced Facebook groups and they made me feel real stupid. On the ftDNA chromosome browser, what significance does that little pinch on the indicator have? Sometimes there will be a match that goes right through it. I hope I am conveying what I mean.
Thanks for your help!
Hi Kathy, sorry to take so long to get back to you. The pinched bit of the Chromosome is called the “Centromere” – its a place which works a little differently from a scientific point of view. When drawing chromosome browsers the sites/apps often show it as pinched up in their drawing. It’s shown because you need to be aware that DNA tests usually show the matching segments as 2 separate segments if they cross the centromere. It is an “odd” region of the chromosome and it’s best to presume that the matching DNA is broken up at that point, rather than presuming it is just one long stretch (which could lead you to assume it is a much closer relative that you are matching with). So always evaluate the match going through the centromere as being 2 separate segments. So if you have a small segment one side and a small segment the other side – it is possible it is just a match by coincidence rather than a match due to descent from a common relative. You need to just determine that by looking at your match in more detail. Hope that makes sense – it is basically a region of the chromosome that needs to be treated with caution.
Hello! My Dad match’s a woman and her two daughters, On his Chromosome 12 Segments start and end in exactly the same places. They cross the centromere for mum and one daughter. And don’t for the other daughter: This is from MyHeritage:
Mum & 1 daughter:
22478847 – 52163789
24.6 cM. 13,952 SNP’s
The other daughter:22478847 – 28931965
Segment size: 9.0 cM
Number of SNPs: 3968
40783688 – 52163789
Segment size: 9.0 cM
Number of SNPs: 5504
The SNP’s seem very high for the mum and daughter who cross. And also strong for the 2nd child each side. And seen to balance all three if these all are genuine, where second girl if crossed looks to me might have same cM and missing area would complete & match her mum & sister. Could this mean the segments for mum & daughter that cross it may be genuine? Is this possible? Also shares segment with the mother on his Chromosome 2 also crosses centromere:
Genomic position:
86018262 – 119751867
23.9 cM SNPs: 11,264
Shares
54.1 cM 3 segments with Mother
35.8 cM 2 segments with sister shares 12 crossing Centromere
48.7 cM with the other daughter 4 segments
I’m very curious about this. Mother of this mother is trying to find how her daughter and Grand daughters are related to Dad, assumes via her deceased husband, in search for his ancestors. So far proving difficult. I’m going to ask her to upload their DNA to GEDMATCH. Would like to see how this looks there. This family are german, Dad’s GM was Prussian, All our relatives through her are on Ancestry but have one falling from my GM brother on GEDMATCH. I’m very curious about this.
Many thanks, Kerryn
This is the clearest explanation of the “big 3” companies I’ve found online. I’ve also never seen the discussion about parents’ vs. grandparents’ DNA, and how testing uncles, cousins, etc. isn’t necessarily going to be helpful, given that we only get 25% of our grandparents’ DNA. Wow. Alas, both of my parents have passed away already. But my brother and I can each be tested (so we’ll get the yDNA info). Thank you very much!
Thank you for your comments Bette, pleased it has been helpful!
You have certainly put some effort into studying the complex makeup of the human and the scientific relationships available today. At 75 its way above my head,but if of any interest to you I’d certainly be interested in participating.I.m a cousin to your father as you will know, so I guess we are in the same grandparent stream. Let me know if you are interested in me participating . Kind regards Hec PS I expect we will meet up again next October in New Plymouth.
Thank you so much, Donna, for this. You’ve written it in simple terms that I think I can follow. I am very new to DNA testing and I struggle with what to do when and next, etc. This is all a whole new learning curve for me. Thanks again! Linda Cormier Tourigny from Saskatchewan Canada
Thank you Linda
Of each newbie site I’ve read, yours is indeed the easiest and clearest. Thanks for writing such a helpful blog and I did click to join on FB. I was beginning to think I’d never get a handle on this DNA. With what you wrote omg I am starting to get it. Wish someone would create a program that would interpret the results of Gedmatch for us. Perhaps in the future someone will and we will look on with pity for the hard way we do it now.
Thanks
Jennie
Thank you Jennie
This would be great (ie better lol ) if done in a short video with visuals. I couldn’t even get into the second paragraph. “At first it seemed sensible enough,” was enough for me to stop and scroll down to see how much I would have to read. Thus I didn’t. Sorry really need the visuals to get to follow along with the point at hand for this sort of stuff.
Sign me
Not a millennial & I own a library worth of books.
If you check YouTube you will find a lot of helpful videos that have been done by the various test companies, and by genetic genealogists (I can recommend anything done by Maurice Gleeson). Everyone learns in different ways, I’m sorry if this way doesn’t work for you.
Thank you so much, very helpful to a new tester. No results yet. I have been researching for last few years. Paper trail is Noord Holland on both sides for about 700 years but am certainly aware that biologically speaking this might not be true lol unfortunately all our older generation have passed but i have 3 brothers and lots of cousins on my mothers side still alive. Do you think testing cousins better than brothers? I will be visiting Holland next year to do some more research and wanted the dna to see if I was going diwnnthe right path. I know I will need all the help I can! My grandmothers (mothers) side her brother moved tonthe states and i am hoping incan find them. Thank you once again, it was easy to read. Cheers Helena. (Melbourne, Australia)
Hi Helena, thank you for your kind words.
There are three types of DNA tests that might help you. The first is the autosomal DNA test, this is the common type of test now for genealogy purposes, it’s really helpful for confirming the past 5-6 generations but is less helpful further back. What you might find though, are cousins who have also extended their research and you could work with them to further your own research.
The other 2 tests are for deep ancestry and can take you back thousands of years.
MtDNA (mitochondrial DNA) is for anybody to take (males or females) and will take your back on your mothers mother mothers .. line. Only women pass down mtDNA but they pass it down to both their male and female children. The test will give you your maternal haplgroup which takes you back to one of the “daughters of eve” (if you’ve not read a Bryan Sykes book on mtDNA, it is a fantastic read). MtDNA mutates very slowly so you may get matching people but the common ancestor could be from many thousands of years ago. MtDNA seems to be the least favourable of all the DNA tests, but there is definitely benefits to be had by knowing your maternal haplogroup.
The other DNA test is the Y chromosome test. This can only be taken by men. This traces the fathers fathers fathers.. line. It gives you a paternal haplgroup. Different levels of testing means you can start with testing a few markers and upgrading to more depending on what you find out and how far you want to extend the test. Y testing is more common than MtDNA, so you will get matches and possibly close ones. The haplogroup enables you to understand your migration on the paternal line from thousands of years ago.
MtDNA and Ydna tests are both available from ftDNA (family tree DNA), they also host many projects you can join to help further understand the tests.
Whilst MtDNA and Y DNA tests are interesting and useful, i generally suggest people start with the autosomal DNA test first … this way you get to see matches across all your tree branches.
Autosomal DNA tests can be taken by males or females, there is no difference. Generally it’s useful to test the eldest generations first, so your parents or grandparents, then yourself.
Hi Donna, as someone only just coming to the DNA side of genealogy I found this very instructive. I will probably start with the Y-DNA test as it may help me prove a missing father five generations back.
One point that I see frequently highlighted is to test the ‘oldest family member first’. That’s me so it doesn’t bring me any great advantage. I have a sister so is there an advantage in both of us taking the autosomal test to hopefully fill some of the gaps from our parents?
Thanks
Testing siblings can be invaluable in autosomal testing, when you cannot test your parent(s). Siblings inherit a different random 50% of each parent, so whilst you will have the same matches at the top of your list (first and second cousins and closer), you will get different matches as you go down the list. So your sibling is basically supplying more of your parents DNA for you to use in your research.