

You’ve got your DNA test back, and now you have a million questions to ask. Here is a list of some questions and answers that might help to get you started. Find out about Mickey Mouse, X DNA, Haplogroups, Clusters, DNAPainter and other third party tools, GEDmatch and much more…
Q: Help! I have my test results – what do I do now?
A: First thing most people do is look at their Ethnicity/Origins percentages – and are usually happy or confused! Check out some questions further down about ethnicity, and why it’s just an estimate. After that take a look at your match list. The match list is the most powerful part of a DNA test, it can help you confirm your family tree, breakdown brick-walls and solve unknown parentage cases such adoptions, foundlings & donor-conceived.
Your match list is ranked from highest match to lowest. Matches are categorised based on the amount of DNA you share, the more DNA you share the closer your relationship is.
Most sites will categorise a match for you but this is just an estimate or category – only genealogy will be able to determine the correct relationship. More about how DNA is measured, and how to work your match list, further down.
Q: Why do my ethnicity results not match my tree?
A: Ethnicity Estimates are just that “estimates”. They can relate to your ancestry from hundreds or even thousands of years ago and therefore will not match your paper trail from the genealogical time period. Ethnicity results are calculated by comparing you to a reference group of people (often called a reference panel). These are people that meet certain criteria requested by the test company (e.g. a reference person might have 4 grandparents all born within 50 miles of each other, all with known Ancestry in that region). Your DNA is compared to these people, often by scanning it several times and taking an average of the readings. Companies are continuing to update their reference panels and udating their ethnicity estimates. Ancestry have updated their estimates yearly and in 2022 added their powerful technology SideView(TM) where they split your ethnicity by parent. My Heritage have promised an ethnicity update “soon” for two years or more, but have only added to their genetic groups.
Q: I’ve tested at another company, or uploaded my DNA at another company, why are my results different?
A: Each test company has a different way of working out ethnicity (sometimes also called admixture). They all use a different reference panel and thereby arrange people into different regions. One company might have a category “Great Britain and Ireland” and another one might split that into two regions. If that particular company does not have a reference person for a specific region, then you will never get that region in your results – even if that is what you are 100%.
How do you know which one is accurate? Well none of them are “accurate”, although Ancestry is considered to be one of the best due to the work the scientists are doing and the continuing updates as they learn more.
Debbie Kennett did an excellent presentation at Family Tree Live in April 2019 that covered everything you need to know about Ethnicity – it is free here online at YouTube
Q: Should I download/upload my DNA to other sites? And which sites can I upload to?
A: Quite often in Facebook groups as soon as someone mentions they have their results back, people start commenting to “Download your raw file and upload to ….” . Whilst uploading to other sites can be a good idea, it can be easier to learn all the necessary details and jargon at your original test site before tackling other sites. Always check the T&Cs and privacy settings of the sites you want to upload to and ensure you are comfortable with them. ftDNA and GEDmatch also have law enforcement matching that you may want to opt-in or opt-out of (note that at GEDmatch you can not opt-out of unidentified human remains work). Many sites accept your DNA for free and some request payment for analysis and use of any tools they provide. Not all upload sites accept files from all test companies, so always check which company files can be uploaded. At this time the majority of Genetic Genealogists recommend testing with Ancestry first (largest database) and uploading to other sites starting with My Heritage
Stay away from the “spammy” sites that say they can match your autosomal DNA to ancient remains. This cannot be done and trying to match your modern DNA to ancient DNA is no more than “genetic astrology”. Jennifer Raff a Geneticist, Anthropologist & Science writer has a great article about this Genetic Astrology: When Ancient DNA Meets Ancestry Testing
Some common sites accepting DNA uploads:
- ftDNA there is a small fee to unlock their chromosome browser and access to My Origins. In 2023 ftDNA started rolling out the paternal haplogroup to males who have uploaded or tested with them. This rollout should complete in 2024. You do need to have unlocked the kit (or tested) with them to get his new feature,
- My Heritage – if uploaded before Dec 2018 then grandfathered into tools for free – after that date there is a fee for DNA tools (if you are not a subscriber). Sometimes they have had free upload days where you would also be grandfathered in. NB: if you test with My Heritage you will need a subscription to use all the DNA tools.
- LivingDNA (for matching only, but you can upgrade for the regional ethnicity breakdown for a fee. Matching is still limited with most people only having a small number). They are adding more features such as Viking DNA, see note above about comparing your autosomal DNA in this way and note there are additional fees.
- GEDmatch a public DNA database now owned by Verogen. The first site allowing Law Enforcement uploads for unidentified human remains and violent crimes. After several iterations of opt-in/opt-out currently you can opt out of criminal case but not unidentified human remains
Note: Ancestry and 23andMe do not accept uploads.
23andMe: At the end of 2023 23andMe had a widely published data breach which was conducted by bad actors who found leaked passwords linked to email addresses. Because many people use the same password and email address at every site, the bad actors were able to access accounts at 23andMe. DNA companies reacted quickly by adopting 2FA (two-factor authentication) to log into your account. Some companies also temporarily removed tools and downloads associated with segment data.
Ancestry: as of 02 February 2024 Ancestry requires a subscription to access some of their DNA tools. A small DNA Plus membership (at around £2 per month) is all that is required. For those wiht a subscription already there ar no changes to what you can do and see with your matches or with your managed kits.
Q: What does my match list mean, how do I use this information?
A: Your match list is usually arranged in order of highest match at the top and lowest match at the bottom. The test sites categorise your DNA into groups of cousins. Usually close family are listed as Immediate or Close Family, but the names of these categories can be different at each site. Although a match might be in say the 2nd cousin category, it does not mean this is a 2nd cousin. Various relationships fall into the same category due to the amount of DNA shared. Things such as half relationships, once or twice removed cousins, or a cousin marriage in that branch can mean the relationship is different than the category it is in. It is key to learn about how to predict a relationship based on the cM shared (cM stands for centimorgan, which is a complex measurement of the amount of DNA you share with someone).
At Ancestry you can find the predicted relationships by clicking on the cM amount in your match list – this will open up a table. The table shows the percentage of the time people sharing that amount of cM have the relationships shown in the list. The more DNA shared, the higher the cM amount and therefore the closer the relationship with the match.
Ancestry example:
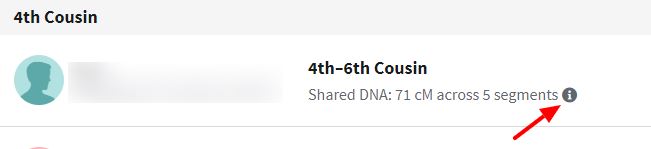

Other ways to predict a relationship: For matches at other sites there is a third party resource called the Shared cM Project . There is more about this site in a couple of questions further on. Some sites (e.g. 23andMe) show your shared DNA as percentage rather than cM (although you can see the cM by looking further into the detail of your match if they are sharing that info with you). The SharedcM tool will take percentages as well as cM amount and also predict the relationships
Remember: The higher the cM amount the closer the most recent common ancestor (mrca) is.
Q: What does shared cM, largest cM and Segment numbers mean?
A: cM = centimorgan, a complex calculation to work out how much DNA you share. The test usually reports the total amount shared as either a cM number or a percentage (23andMe). They also usually show how many segments this includes. A segment is just a block of DNA you share. For most people the number of segments doesn’t really help determine a relationship. In distant relationships the number of segments is usually 1, i.e. just one small block of DNA is shared. The segments are often on one or more chromosomes – we’ll cover off chromosomes later. Most people can ignore segment numbers.
Some sites will show a third number, and that is the largest block or largest segment. So a match might be 40cM / 2 segments and 25cM longest block. This means the total amount of DNA Shared (the most meaningful number) is 40cM. The DNA is on 2 segments, one is 25cM (the longest block) and so the other must then be 15cM. The most relevant number is the amount of total shared cM as this will help you predict a relationship.
Note: DNA results of someone from an endogamous population will find the longest segment information the most useful. Endogamous populations are where there have been multiple cousin marriages over the generations (not to be confused with Pedigree Collapse which is where there is only one or two cousin marriages in a branch).
Q: How do I know what relationship the match is to me?
A: As above the test site will give you a prediction, ie 2nd cousin, 3rd cousin etc. But these are high level estimates only (more like a category) – based on the cM number. There are charts available to help you look at various possible relationships. The ISOGG wiki (International Society of Genetic Genealogy) has a huge amount of useful data, one of those is the Autosomal sharing statistics. The Autosomal DNA Statistics page has three charts, one that shows the various relationships in a family tree, one that shows the average likely relationship based on cM shared, and the last chart has a range of reported cM numbers by many people who have been confirming their DNA matches. The ranges are really helpful and can see that some cM amounts could mean many different relationships.
The third party tool previously mentioned in this blog is the SharedcM Project and is available in the tools section of the DNApainter site. This tool is really useful as you can type in the cM amount of your match and all the various possibilities will be highlighted. This is invaluable for genetic genealogists – so make sure you bookmark this site. As previously mentioned, if you have tested at Ancestry they have a chart that pops up when you click on the cM amount of your match and this is the preferred way to predict a relationship at Ancestry.
Once you have a predicted relationship, it is only by building family trees that you can work out exactly what the paper trail relationship is. Note that if your paper trail says someone is your second cousin, but the DNA does not fit into the range reported, then you have a mystery to solve. Maybe they are only your half second cousin, in this case look for other shared matches to see what might be going on, are they also matching lots of unexpected families? (or are you not matching a lot of your own family?). Unfortunately DNA can produce some surprises, not all of them good ones.
There are other relationship prediction tools available, My Heritage have built in their “cM explainer” tool and GEDmatch have included the dna-sci.com tool.
DNA research requires a lot of traditional tree building, so it helps to also get skilled up on traditional genealogy research. The actual relationship requires tree-building to establish exactly who your match is and their relationship to you. When the relationship is found through genealogy it should fit the cM amount.
Q: How can I work out if my match is paternal or maternal?

A: The test itself cannot tell you this* The best way to do this is to test a parent, as then any match that doesn’t match them, must be the other side. Of course not everyone can test a parent, so the next best is an aunt or uncle – they will help work out which matches are their side, but you cannot make the same assumption about those they do not match … some of those could still be their side, they just did not get the same DNA as your parent did (see the DNA inheritance question further on). First cousins can also be helpful as then you can pinpoint Grandparents that the match belongs to. Once you start confirming matches, shared matches will really help. As I’ve confirmed a lot of 3rd cousins as soon as a new close matches comes in I can click on shared matches and almost place the new match immediately in a tree branch, based on who they share DNA with in my list. Be aware that many genetic genealogists have found a high percentage of their small matches do not match either of their tested parents. This is called a “false positive” match as we can only get DNA from our parents. False positives start around 20cM and under at Ancestry, but as high as 45-50cM at My Heritage (due to the imputation technique they use for matching with uploaded kits).
A good blog on this topic from Debbie Kennett
*SideView (AncestryDNA) In 2022 Ancestry rolled out their powerful SideView tool for matches. The tool is able to establish (using DNA) which side your match is on and label them Parent 1 and Parent 2. This is the same tool that was used for rolling out the Ethnicity Estimate view by parent (again by Parent 1 and Parent 2). Users are able to update the label and call Parent 1 “Maternal” for example, which will in turn change Parent 2 to “Paternal”. It’s important to note that Parent 1 is NOT Maternal for all users, for some it will be Paternal, you need to decide. Some users have found that they initially labelled Parent 1 and 2 the wrong way round when looking at Ethnicity and have had to update the assignment. Note that Ancestry can not assign all matches and some will be “unassigned”. Assigning a side is done periodically so new tests may not have it for a while. Some users will get “both sides” matches and this often causes distress or confusion. A both sides match does not mean your parents are related, for example if a matches fathers side is related to your paternal side and their mother is related to your maternal side, they will be a both sides match to you. Sometimes a close relationship such as a half sibling might show as “both sides” which on face value appears unusual, but it may be two very small segments are related to your other parent side, more distant than you will be able to solve. Ancestry have announced that they are working on Grandparents sides, possibly due to roll out in 2024 (although no official communication has been made).
A good blog on this topic from “The DNA Geek”
Q: Will I match DNA with all my cousins?
A: No you won’t! Currently it’s never been found that a 2nd cousin will not share DNA, so if you are not sharing DNA with a known second cousin (who has also tested at the same site) then you have a mystery to solve, something is not right. But more distant than 2nd cousin and it’s possible to no longer have any DNA from the shared ancestor (see further down for details of how DNA inheritance works). This is generally around 10% of 3rd cousins who will not match you, up to 50% of 4th cousins and 70% of 5 cousins. It can vary of course, but these are high level numbers, so don’t be surprised if a known 4th cousin does not share DNA with you, it does not mean your paper trail is wrong and more research is needed to confirm the branch.
Info from ISOGG Wiki on Cousin Statistics
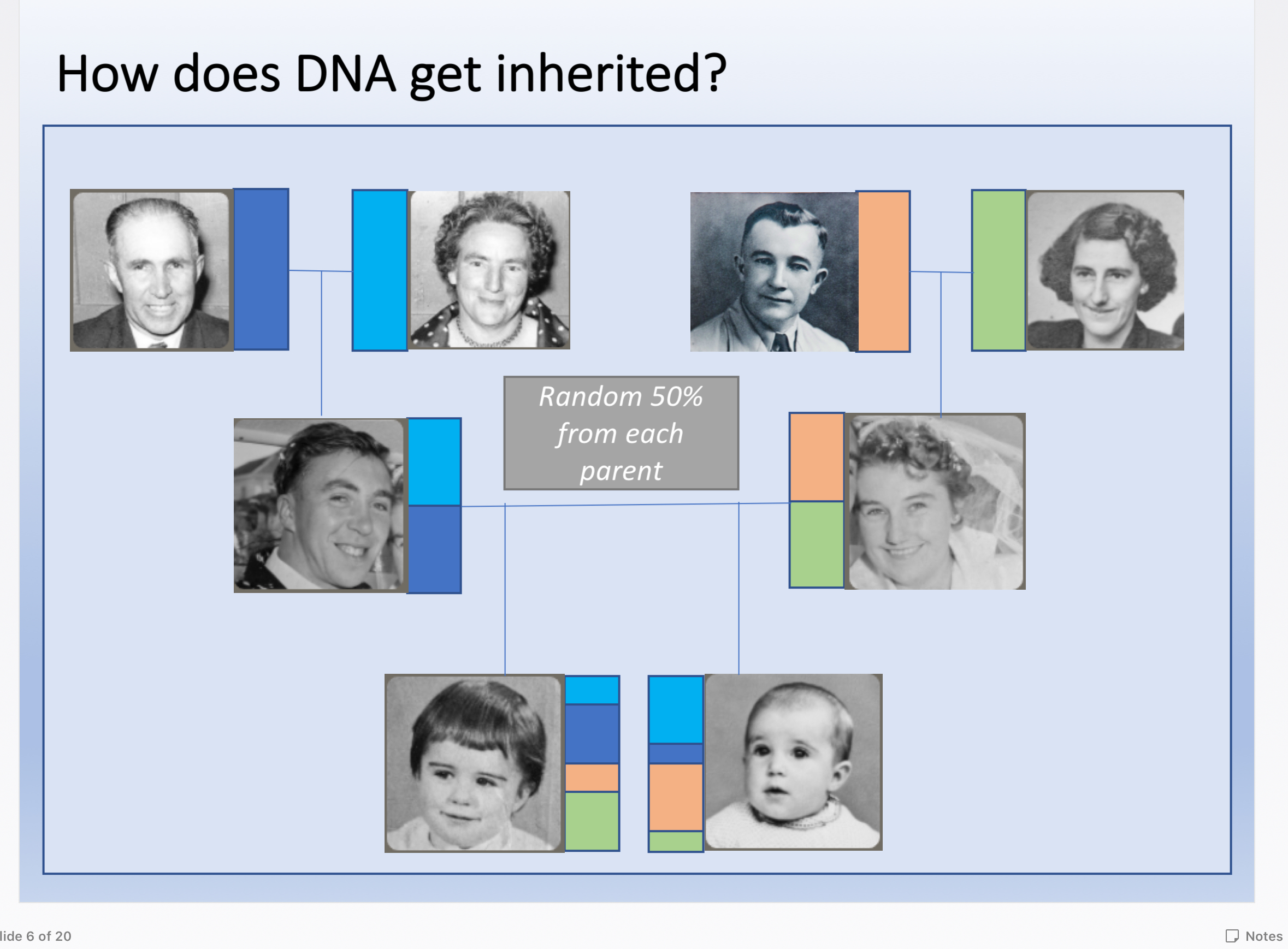
Q: Can I inherit DNA from my grandparents that has skipped my parents? Does DNA skip a generation?
A: No this is not biologically possible. Everybody gets a random 50% of their biological parents, which is a random “recombined” version of the DNA they got from their parents. This means that you do not end up with an exact 25% of your grandparents, and also explains why your siblings will have different DNA than you, in fact they will have a different ethnicity estimate and different matches (there will be some commonality though, and full siblings will share all their matches down to 2nd cousin level). Here is my chart showing how DNA inheritance works using colours to represent DNA.
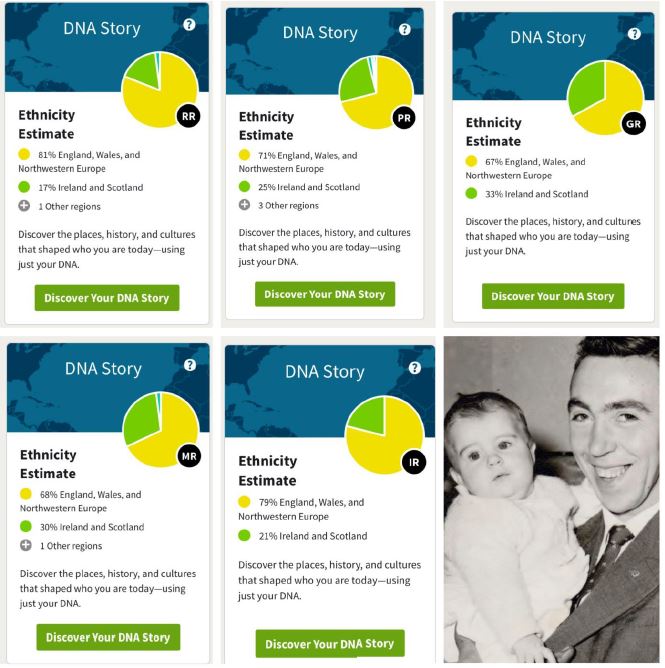
And here are the ethnicity estimates, from the Ancestry site, for my Dad’s five siblings (proven full siblings)
Q: None of my matches seem to have family trees attached, and none of them are answering my messages – has DNA testing been a waste of time? Why do people bother to test and then not share anything?
A: Most certainly your test has not been a waste of time even if your matches do not have trees and do not reply to you. This has been the most common complaint from genetic genealogists over the past few years. Here are the cold hard facts: when someone got given a DNA test, or paid for a DNA test, or was requested by a family member to do a DNA test … at no time during that process were they buying into communicating with other people, replying to messages, sharing their tree, or for some even bothering to look at it again after they first got it! It’s not for us to wonder why, or have unrealistic expectations that everyone is like us and want to get about researching their tree. Also remember that many testers are adoptees and foundlings, firstly they do not have a tree to share, and secondly they are often warned off communicating too much about being an adoptee, sadly not everyone wants to help them. So what can we do about it? Well as it turns out, actually quite a lot!! If you have a match with a private tree there are tricks to figure those out too, check the next question for private trees .
SLEUTHING, how to become a Genetic Detective 🕵️ : Researching DNA matches without trees – my long list of things to do:

– open the dna profile page and check if they do have a tree but just not linked (Ancestry) <- about 75% of the people with no trees, do actually have a tree. (If you’ve not linked your DNA to a tree.. go and do it now!)
– go to their main profile page at Ancestry, look for clues as to how long they have been researching (if a long time, then they may have a tree on another site)
– check their main page for age range and location … sometimes people put a LOT of really useful info on their profile
– google their name/ profile name using some of the clues you may have found – looking for possible hits on who they are. Learn to do advanced google searches. For ftDNA & GEDmatch matches google their email address to see if they have a tree somewhere else, or family information online .
– write all your clues down, tick them off or cross them out as you validate them/invalidate them.
– look for possible trees at wikitree, geni, genes reunited, My Heritage, FMP, etc..
– if you’ve now established a possible name, check 192 dot com, white pages, electoral rolls, pipl, etc … where you might find details about them
– search for Online obituary’s (especially useful if the match is in the US as they often list all their family in detail)
– bear in mind woman testers often use their married name
– on the matches DNA profile page, click on “shared matches”… who else do they match ? You might be able to research the group of shared matches together, working off clues from the shared matches trees. Shared Matches can be gold when trying to identify and solve a match without a tree.
– if they are at Ancestry check if they’ve uploaded to My Heritage, ftDNA or GEDmatch.. can you identify them there (if you can now you will have an email address, for more google searching) .. and also a new set of people who match you both
-start building a “research” tree for them , keep it private and unsearchable .. it’s “quick and dirty” so add hints, extra people, whatever you need to try and establish who your match is and their ancestors. This type of tree is often called a “Quick & Dirty tree” – due to the fact you are doing it quickly (accept hints if using an online tree), and dirty in that you are not looking for sources at this point you are copying other peoples tree or using hints. It is better to have just one “research tree” so add all matches into it and edit their relationships to make them standalone. Build out the tree of your match to find the common ancestor.
BUT … Keep in mind you may get nowhere, in which case you research hasn’t gone to waste … maybe tomorrow they decide to create a tree, or they get a new shared match that opens up better clues. (Keep your notes! I add mine to the matches name in my Research tree).
As you start pulling together your hypothesis of who the match is, and how they relate to you, always go back and try and disprove it, don’t get caught out with confirmation bias where you only look for clues to prove your theory, more importantly look for clues to disprove it! This includes once you find the match, to go back and check that the DNA could not have come from another relative!
If you are looking at what the predicted relationship might be, see the earlier questions on how to do this.
Recently some people have challenged the privacy and ethics of researching people in this way. In no way are you doing anything illegal by searching public information to find out about your match (your cousin in fact). But please keep your research private, if you come across something your match (your cousin) probably doesn’t want published, please think of them and be ethical about sharing information you’ve discovered. Any speculative trees you make should be private and unsearchable. If a situation seems delicate, please treat it as such.
Here are some more resources on how to identify your match and/or create quick and dirty trees
- https://www.rootstech.org/video/a-dna-match-with-no-tree-no-problem
- https://www.familytreemagazine.com/premium/no-tree-dna-matches/
- Crista Cowen (Ancestry) using quick and dirty trees https://youtu.be/VP8rUlZbmeA
- https://thegeneticgenealogist.com/2017/03/11/are-you-doing-everything-to-identify-your-matches/
- Look out for my talk “The Genetic Detective”
Q: My match has a tree, but it’s private and they are not responding to messages, how can I work with this match?

A: The first thing you should know about private trees is that when you search your Ancestry matches, the results include private trees. So by quickly doing a few searches, using names in your tree, you can establish which names they also have in that private tree. This can help to confirm a branch they may be related on. Also use some of the tricks and tips above and especially look at Shared Matches … this can tease out exactly where this match might sit in your tree.
Q: At Ancestry I have Common Ancestor Hints and ThruLines – can I just accept these as how I share DNA with my match.
A: In short No. These are tree hints, the Ancestry algorithm has found that you and your match has someone that looks the same in their tree, or the Ancestry algorithm has been able to stitch together a genealogical tree from all the trees they have in their database. These are not “DNA Hints” – they are “Tree Hints” so beware.
The common ancestor hints & the ThruLines pick up an ancestor that it thinks is both in your tree and your ancestors tree, but sometimes the “same name” isn’t actually the same person, so you must check. Also if your match just copied your tree then you will, of course, also have the same name in your tree. My old saying is that if you have Mickey and Minnie Mouse in your tree and your match copies it, then you will get a Common Ancestor hint and a ThruLine showing you are descended from the Mouse family – of course you are not.

So all hints require further research BUT they are often a very good place to start. They can be excellent, but they can also be wrong – so please take care to always do more research on a ThruLine.
!Do not fall into the trap of moving your DNA around to try and manipulate ThruLines, if your match sees this they may copy your tree and bingo you will get a ThruLine. This warning also refers to adding speculative people to your tree. We have enough and trees at Ancestry without genetic genealogists trying to manipulate the system and add speculative ancestors.
Crista Cowen (Ancestry) has presented a great video on What are Thru lines
Q: I’ve uploaded to GEDmatch, but I’m lost and it’s confusing, what does it all mean?
A: GEDmatch is a public DNA database that was previously run by volunteers, it is more technical than the test sites themselves and can often appear confusing. At the end of 2019 GEDMatch was sold to Verogen and at the start of 2023 Verogen was bought by Quiagen. Details here. During 2019 GEDMatch came under fire for allowing Law Enforcement use of their database – without properly alerting their users. Much of the Law Enforcement advancement into Genetic Genealogy came around the time the Golden State Killer was identified by using genetic genealogy. Many other doe cases & law enforcement cases have followed – often with much discussion from the Genealogy community who have been using DNA databases for genealogy and not expecting their use for law enforcement. Everyone has different opinions on what should & shouldn’t be allowed. Ethically this is something each genetic genealogist needs to determine for themselves. Genetic Genealogists should also act ethically with kits they manage for other people – is there Informed Consent for your testers and have they agreed to what you do with their DNA data. Later ftDNA went on to also allow Law Enforcement to match kits in their database. At both ftDNA & GEDMatch you can opt-in or opt-out of Law Enforcement matching (at GEDmatch you cannot opt-out of Unidentified Human Remains matching).
https://isogg.org/wiki/GEDmatch
Q: What is X DNA and how can I use it in my research?
A: X DNA is the DNA on the the X chromosome (chromosome 23) . We all have 23 pairs of chromosomes from our parents (22 of these are called the Autosomes, hence the term Autosomal DNA) – one of each chromosome from our mother and one of each from our father. A mother passes a recombined X DNA from her two X chromosomes and a father determines the sex of a baby by either handing down an X chromosome for a biological female, or a Y chromosome for a biological male. This means some one born male only has one X chromosome and he must have got that from his mother. This makes it X DNA a useful tool to help sorting out your matches, as if you are a male tester and match someone that shares significant DNA on the X chromosome, then it must come from your maternal side. However the X chromosome should be used carefully – some experts say that the X DNA should be at least 15cM before being meaningful, and if you don’t share any DNA other than X, then it may be a very distant match that you would be chasing. When you have a match with X DNA you can fill out an “inheritance chart” to help highlight where the DNA could have come from (as it cannot be passed from a father to son). There are two charts, one for a Female as she will have X DNA from her mother and father) and one for a Male (as he can only have X DNA from his mother).
Blaine Bettinger has a great blog on this topic, including the X Inheritance charts that you can use
Q: I’m working with my match and we both have well researched trees, why can we not find the common ancestor, or why can we not find a common surname?
A: Here is my list of reasons why you may not find a common ancestor.
If you cannot figure out how you are related to somebody, because their tree and your tree do not have the same names in it – then it could be for one of the following reasons:
1. Your tree is wrong or does not go far enough back to find a common ancestor. Keep building out your tree, you should be able to get a rough prediction of where the most recent common ancestor is, based on the amount (cM) of DNA you share.
2. Their tree is wrong or does not go far enough back to find a common ancestor … in this case you need to do the research in their tree yourself. I do this by starting a private (and unsearchable tree), and starting with their parents or grandparents build up the tree trying to find a location in common. Don’t get too hung up on surnames, look for places where your ancestors have crossed paths
3. There is an NPE (Non Paternal Event, sometimes these days called MPE, Misattributed Parent Event or similar) in your tree. If you are finding a lot of trees that don’t match your own, or family that have tested that do not match you as expected, then maybe there is a broken line where the father named in the source document is not the actual biological father.
4. There is an NPE in the matches tree. In this case look at shared matches, and see if you can find where the matches tree might be wrong. In these cases it’s often easier to contact the match and try and research with them.
5. The common ancestor is back before the genealogical time frame, i.e. a segment of DNA has passed through the generations unbroken and you will never find the common ancestor. These segments of DNA are often called sticky segments (although that term is going out of favour). There are specific known areas that are prone to this (called known pile up regions). Ancestry’s matching algorithm does remove those.
6. The DNA match is false, a small match under say 10cM may just be a coincidence rather than a real match. If you have tested both parents you can easily find a false positive match, because they will not either of your parents.
Q; The same match at another site seems to share a different amount of DNA with me – how can that be?
A: Each test site uses a different matching algorithm to create what they call a match. Ancestry has a sophisticated algorithm they call Timber and it down-weights segments of DNA that are considered to be shared due to a population rather than a recent common ancestor. This means that the Ancestry site might report a lower number than another company.
Q: What is a Haplogroup? And how do I find mine?
A: Haplogroups https://isogg.org/wiki/Haplogroup come in two types, maternal and paternal, and they pertain to our ‘deep ancestry’ ie they show our maternal (mother’s mother’s mother’s… line) or paternal line (father’s father’s father’s line …). The haplogroup is a type of “family name” for people who have similar DNA “Mutations” (mutations shouldn’t be considered bad here, it just means the code you have at specific places in your DNA) .
Everybody can be assigned a maternal haplogroup if they test their mitochondrial DNA. This a special type of DNA that surrounds the nucleus of the cell, it is not on a chromosome. Everybody has mitochondrial DNA (MtDNA) but they only get it from their mothers. Men do not pass down any MtDNA . So males and females can take the test, and sometimes a high level haplogroup can be assigned by testing a very small part of your mtDNA and this is often combined with a autosomal DNA test (23andMe and LivingDNA do this). Usually when this is done you would not get any MtDNA matches, just the high level haplogroup. ftDNA do full MtDNA tests that give you a final haplogroup and matches. But one note of caution with MtDNA tests, MtDNA mutates very slowly so when you get an extremely close match, it could mean the most recent common ancestor lived over 1,000 years ago. So this may not be the best test to take if you are looking for matches within the genealogical timeframe. More info here at ISOGG https://isogg.org/wiki/Mitochondrial_DNA_haplogroup

The second type of haplogroup comes from the Y chromosome, and therefore the test is only available for males. Many woman ask their brothers, fathers, or uncles to take the test for them. Like MtDNA a high level haplogroup can be estimated, but more detailed testing is required to get a more detailed haplogroup. FtDNA also offer Y DNA tests, both the marker test (STRs) and SNP tests. When you match someone with the same haplogroup, this does NOT mean you match each other within the genealogical timeframe, or that you even match each other on your father’s father’s father’s line. Within your family tree, you would have many many haplogroups, but when testing yourself you are only seeing the very limited lines of father’s father’s father’s line… or mother’s mother’s mother’s lines. Haplogroups are amazing and interesting, as are Y DNA and MtDNA tests, so it’s well worth finding out more if you want to go down this route. More great information on Y DNA tests here from ISOGG https://isogg.org/wiki/Y_chromosome_DNA_tests
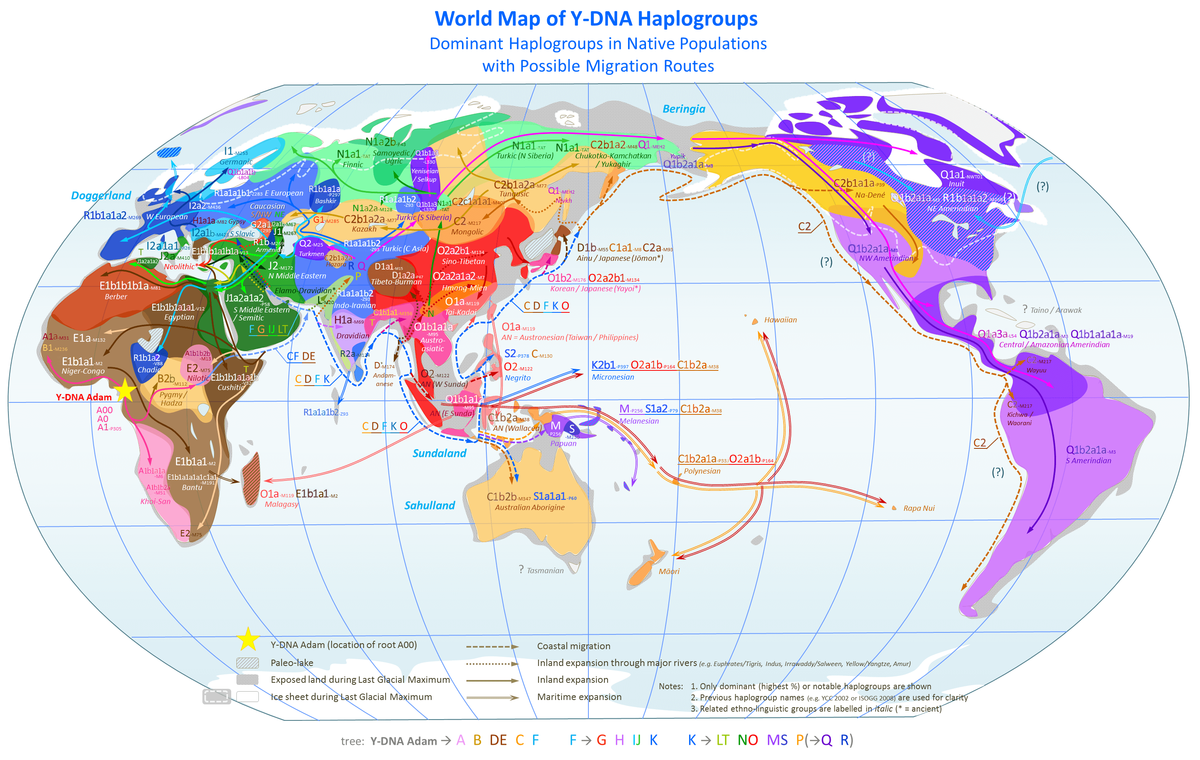
At the end of 2023 ftDNA started rolling out Paternal haplogroups for people who had tested with them (Family Finder) and people who had uploaded their autosomal DNA test. This will be for males only and will require an uploaded kit to be unlocked (see the upload question further up the blog).
Q: I’ve found several matches that all match me at the same location on the same chromosome – does this mean we all have the same common ancestor?
A: You cannot answer that until you do further steps. You must do one on one matching with each match (with each other) in turn. So for 4 matches you need to check A-B, A-C, A-D, B-C, B-D, C-D. This is because you are looking at a pair of chromosomes stacked on top of one another, your paternal chromosome and your maternal chromosome. Some of the matches will be paternal to you (they will all match each other, but not everyone) and some will be maternal to you (they will match each other but not anyone in the first group). Each group can now be considered to have the same common ancestor, but you need to figure out which group is maternal and which is paternal. They must all overlap for at least 7cM or more to be considered a real match. Note that this can be easily done at GEDMatch, My Heritage and 23andMe where you can check your matches against one another, but at ftDNA you can only check matches against yourself! Ftdna have a tool called the matrix which can be used to see if you all match each other, however you can only make an assumption as the matrix does not show the chromosome number, just high level whether someone matches another. At Ancestry you cannot see any chromosome or segment data, therefore you need to use Shared Matches, but again you will not be able to confirm if they are all the same common ancestor.

Q: How small a match should I go chasing to find a common ancestor?
A: It is personal preference really. Anything under 7cM is considered to be more likely to be a false positive. I personally don’t chase matches that are likely more distant than about 4th – 5th cousin, this is firstly due to the number of matches I have across many kits, but also the chances of actually finding a common ancestor at that range becomes much harder … bearing in mind that source documents are harder to find, women’s maiden names may not be recorded, and there is more chance of errors on trees, and NPEs causing confusion. Even if you find a common ancestor with a potential 8th cousin (because you have the same tree, bear in mind the Mickey Mouse theory above, but also at such a small amount of shared DNA you cannot confirm the DNA was from that particular ancestor and not another unknown ancestor branch on your tree). I leave small matches alone, unless they have good genealogy and I do use that to place them in my tree (however I am fully aware the DNA does not necessarily confirm that genealogical connection).
Here is a great blog from Blaine Bettinger regarding small matches a small segment round- up and a fantastic follow-up to this is his 2022 An In-Depth Analysis of the Use of Small Segments as Genealogical Evidence.
Q: There is no chromosome browser at Ancestry – do I need one?
A: Although a chromosome browser can be useful to solve some very particular puzzles, for the majority of genetic genealogy work you will not need a chromosome browser. The best and most productive method of using your DNA matches is to work with your DNA groups of shared matches, build a quick & dirty tree and see how they are connected. The common ancestor of a group of shared matches is most likely your common ancestor.
A group of matches that have a common ancestor do not necessarily all share the same segments on a chromosome. Sharing all the same segments on the same chromosome is called “Triangulation”, but again using triangulated segments is not the most productive method of genetic genealogy.
An interesting blog by Diahan Southard on using Chromosome Browsers
Q: I’ve heard about Clusters and the Dana Leeds method – what is that about?
A: Using Shared Matches has become the powerhouse of DNA research and “Clustering” is the term used when working with groups of shared matches. Generally speaking a group of matches that also match each other is likely to have the same common ancestor. This common ancestor is also likely to be your common ancestor. The theory is that if you solve the group (or cluster) of shared matches, you can work out your connection to them. If the common ancestor of the group is not in your tree, you may have a mystery to solve.
Finding shared matches is quite easy on most of the test sites. Ancestry and My Heritage go a step further and allow you to colour code your matches into groups using coloured dots. This can be really helpful as you can colour code your matches however you like. I suggest you colour code them based on the group of shared matches. One method of clustering to find 4 groups of matches for each of your grandparent branches was documented by Dana Leeds in a series of blogs. You take your top match (starting around 400cM), check the shared matches and then colour code them all the same colour – thereby creating a cluster ready for you to try and identify yours (and their) common ancestor. The Leeds method suggests starting with matches of 400cM and clustering to 90cM. If you don’t have many high matches it is better to cluster down to about 40cM or even 30cM. Any lower and it can become quite complicated. These clusters or groups are like “Genetic Networks” within your match list. The “Leeds Method” used a spreadsheet (Google sheets or excel are good spreadsheet applications) but it can be much simpler just using the coloured dot system.
A great third party tool available to automate clustering was developed by EJ Blom at Genetic Affairs. This same tool is embedded in the My Heritage tools (“Auto Clustering”) and is also available via the Tier 1 tools at GEDMatch. Genetic Affairs is also supported by a Facebook User Group. This is not applicable to the Ancestry site.
Clustering your shared matches is going to be the most useful first part of your DNA research, but don’t over-think it, the real work is in building trees … Genetic Genealogy is all about the Genealogy!
During 2020 I recorded a video on how to do clustering and use this method to solve your matches, and to solve unknown parentage. It is available in the featured section of my Facebook group (link below) and also on my YouTube channel
https://youtu.be/5yfAfpANktg
Q: What is DNAPainter – I hear this all the time, but what actually is it?
A: One of the most useful third party sites is DNAPainter , it is a fantastic site that houses not just the DNAPainter tool itself but also the SharedcM Project chart, the WATO (What Are The Odds) tool and more.
- The actual DNAPainter tool is for mapping your chromosomes. This means taking segment data where you share with your match and “painting” it on to a blank chromosome. If you know the common ancestor of that match, then you now know that the DNA on that part of your Chromosome is from that ancestor. You need segment data to do chromosome mapping. Segment data is available at ftDNA, My Heritage, GEDMatch and 23andMe (but not at Ancestry). The tool is supported by a Facebook User Group.
- WATO – this tool is fantastic to help work out the mathematics of placing yourself amongst your DNA matches. Invaluable if you do not know you connect to a group/cluster of matches. You start the tool by adding the common ancestor of the group and charting out how your matches connect to that ancestor. Then you add various hypothesis points to the chart (or click the button to have them automatically added)- each hypothesis gives you a score against the previous hypothesis – as you work on it you can gain more clarity about where you are likely to fit with this cluster. The tool is supported by a Facebook User Group.
Some other helpful links:
– Acronyms – here is a list of them all https://isogg.org/wiki/Abbreviations
– GEDmatch admixture calculators – a great explanatory blog http://genealogical-musings.blogspot.co.uk/2017/04/finally-gedmatch-admixture-guide.html
Some of my favourite blogs and bloggers:
https://mobile.twitter.com/genealogylass?lang=en
An unscripted interview with me at Family Tree Live
Some of my beginners talks online Please note some of these were filmed with a live audience and there will be some, hopefully minimal, background noise
Testing for Genealogy the basics
Making the Most of your DNA test
Autosomal DNA testing for beginners
I am also on X (formerly Twitter) as @donnasr
And of course my Facebook Group that was set up to help both beginners and advanced users, specialising in those with UK ancestry.
https://www.facebook.com/groups/AncestryUKDNA

You can contact me at ds.rutherford@gmail.com – I do take some private clients and I’m always interested in discussing foundling cases and will work on those pro-bono. I specialise in solving tricky and complex DNA cases.



{kind=link}
{kind=link}
39 thoughts on “FAQ 2024 – archived”
Thank you Donna. I found your blog much easier to understand than the u tubes I have been watching ,I prefer to read information ,I take. It in easyier ,, I am going to do the one to one matches ,& then go back to my trees ,& do more searching x
Thank you Beverley – pleased it was helpful!
Lots of good information. Maybe too much. Can you outline a sequence of blogs/sites etc., to read to understand this better?
I have been pursuing DNA as it relates to genealogy for about 2 years, trying to learn as much as possisble in my pursuit to identify my unknown family. (Unknown parents of my maternal great grandparents). I’ve read similar lists of information for genealogy/dna beginers, but yours is the most concise, easy to understand list I’ve read. Thank you!
Thank you!
I downloaded the dna for both parents but, there is no X chromosome info on either. Did I do something wrong?
Which site did you test at? Most companies do test the X if even they do not use it in their comparisons.
…thank you so much for sharing information and helping us with tips , result of your long hours of research and probably frequently quite frustrating 🙂
Hope it can be of help – thanks!
You are welcome, happy to be of help.
This article is brilliant. Very simply put for the raw beginner, and all the questions answered. Thank you
Thank you Vanessa
Incredibly helpful, thank you. Relatively concise, straightforward. Look forward to studying your suggestions in more detail.
Thank you Roger
Excellent article. Easy to inderstand!
Thank you Suzanne
I have been searching for several years to try to find the origins of my Great X 3 Grandfather. I had my DNA tested and my 1st cousin also had his DNA tested. We both have the same Grandfather, great-Grandfather, Great-great-Grandfather and the above Great-great-great-Grandfather. I have a few matches who fit into this descending line and I have singled out those who come from the same County as our Common Ancestor. Is it possible to find this ancestor’s origins? and have you any hints that might help me to get started on this quest? I have no parents, aunts, uncles or siblings to whom I can ask to take a DNA test. Just a few cousins. I thought the Painter might be a useful tool to help me, but I’m not sure how!
Donna just to make it clear on my last post, my thoughts are that if I have a DNA cousin who has the same common ancestor as me, then both trees should be correct. Am I right in thinking this, I am hoping that this would be the proof I need that I have found the right ancestor.
Thank you Vanessa Cartwright
This is a great synopsis of EVERYTHING. I’m saving it to share with the many people who ask me questions!
Thanks,
Renate
Thank you! standby for a 2019 updated version very soon!
Donna I hope you can help me for I cannot think what my next step should be. I have been looking for my ancestor for over six years and I think I found him.
On Ancestry DNA I put in a search for someone who had an interest in the name Armitage in Wakefield Yorkshire. There was only one person, a distant cousin, and I asked her if I could see her tree (as she had it private). There I found that she had Armitage and Wakefield present in her tree.
I have a file for each Armitage family in Wakefield. My distant cousin’s tree was one of the one of these files. The family were descendants of John Armitage of Osett who was born 1607. I also have a file for my lost ancestor (who I think I have found) This family is descended from Joseph Armitage of Ossett & Thornhill born 1610. These two, John and Joseph, are brothers their father being John Armitage (Birth unknown but possible death date of 1619 in Thornhill.
This adds up to approximately 9 generations away for me and maybe 10 generations away for my distant cousin, which seems too many generations for the amount of DNA my distant cousin and I have between us which is 14cMs on one segment.
I would like to know if there is any chance of solving this scenario, Many thanks
Vanessa Cartwright
Very helpful and easy to understand article. thankyou.
Thank you
THank you Donna for this detailed overview, really helpful as I start out on this journey.
Thank you Melanie, please it was helpful
Thank you for your very interesting blog, Donna. I wonder if you have ever come across a situation like this: My female first cousin (my mother’s sister’s daughter) carried out an Ancestry DNA test late last year and as expected our shared DNA is 808 cM across 35 segments. Just what I expected for a first cousin and so far so good!
But, when I looked at our shared matches, my cousin shares none of the DNA matches that I have for both my maternal grandfather and maternal grandmother’s ancestors!
We have twelve shared matches ranging from 22 to 32 cM, but none mean anything to me at the moment, despite contacting several of them.
I’d be very interested in your thoughts. Many thanks, John
Thanks you for that, very informative. But may I ask about the little “i” to the right of the “Shared DNA:xxx across xx segments”? I don’t have any of those, am I missing something please?
The little I has now been removed and the cM amount is now a link that you can click.
I’ve just read your updated 2022 version. It is excellent. Well done Donna!
Thank you Trevor!
Wow! This is absolutely THE VERY BEST DNA analysis I’ve come across. A wonderful, well written, treatise that says it all. Thank you. This information should be required reading by anyone contemplating DNA testing……and also those who have already been tested. Very valuable and informative.
Thank you so much! I’m so pleased it’s useful
Very informative
Thank you
Thanks Donna for all your knowledge, really appreciated your blog. When two siblings do a DNA test, why can we not see whether they are full or half siblings? We only get how they relate to us.
On Ancestry you will see if they are full sibling or sibling. The way that Ancestry can tell is by looking at FIRs (Fully Identical Regions), meaning that various segments of your DNA will be matching on both the maternal AND paternal chromosomes at the same spot. If there are enough FIRs then you are full siblings. If there are no FIRs (only what they call half identical regions HIR), then you will be half siblings. 23andMe go one step further and include the fully identical regions so that makes the shared cM seem very high, but they count all the additional FIRs. You can work it out yourself by either using the shared cM amount (approx 1700 cM for a half sibling, or 2500cM for a full sibling … bear in mind the 23andMe trick of including FIRs), or if both female you can upload both kits to GEDMatch and check you share a full X chromosome. Two females that share a father will share one whole X chromosome (190cM). Two females that are expected full sisters and do not share a full X chromosome cannot be full siblings.
I’m on Ancestry, and have my DNA results with them. How do I get a GED match #? Does it affect my Ancestry DNA account?
You need to download your raw DNA file (it’s text file) from Ancestry, you can do that from the DNA settings page. Then you use that file to upload to other sites. It does not affect anything on your DNA site. You should keep your raw file safe, after all it does contain your DNA code for the markers that are tested by that DNA company.